AI & Automation
The New Deal Team: How AI Is Changing Every Role in M&A
AI is reshaping every role on the M&A deal team — from analyst to partner. Here's what that means for the firms building for the next generation of dealmaking.



When it comes to sourcing, the question on seemingly every dealmaker’s lips is, “Can we just use Claude?”
It's a reasonable question. LLMs like Claude are user-friendly, and they return results within seconds. They’re also often cheaper than buying a subscription to a purpose-built dealmaking platform.
And the short answer is yes — partially. If you ask Claude to build a market map or generate a target list, it will produce something useful. That could be a framework, the most visible players in a sector, or a first-pass comp set.
But useful isn't the same as complete. Claude draws from publicly available information, which means it misses the fragmented, under-the-radar middle-market companies that often represent the best opportunities.
The question dealmakers should be asking is, “How do you build an AI-native deal sourcing engine that actually works?”
In this step-by-step guide, we break down how to combine popular AI tools like Claude with private market intelligence platforms like Grata to build a reliable, scalable system.
Every sourcing engine starts with a thesis. AI is genuinely useful here because it helps teams reason faster, synthesize, and structure hypotheses more rigorously.
Claude can help deal teams:
The key is to treat Claude as a reasoning partner, not a discovery engine.
Example prompt:
"Summarize the fragmentation dynamics in industrial field services software and identify characteristics that make the sector attractive for buy-and-build strategies."
A well-structured prompt like this might return a useful synthesis of regional fragmentation, recurring revenue dynamics, labor inefficiencies, succession risk patterns, and low software penetration rates. All of that is valuable for building a thesis.
But it won't return a complete target universe. Claude will surface companies with enough public presence to have generated indexable content — which already excludes a meaningful share of the middle market. That's a structural limitation of the underlying data.
Use AI to sharpen your thesis, then turn to purpose-built private market intelligence to execute it.
Additional Reading:
Before you can execute on your thesis, there needs to be a market to search. This is where generic AI workflows hit their ceiling.
Private markets are hard to see. Most middle-market companies have limited press coverage, scant LinkedIn presence, no investor relations pages, and no reported financials. Many operate within niche verticals where the industry taxonomy itself is ambiguous. Ownership is often unclear. Even company names can be inconsistent across databases and filings.
Generic AI tools inherit all of these limitations because they synthesize what's publicly available. For large-cap public companies, that's a rich dataset. For a $15M EBITDA regional distributor in a fragmented industrial vertical, it might be a single website page and a few LinkedIn profiles.
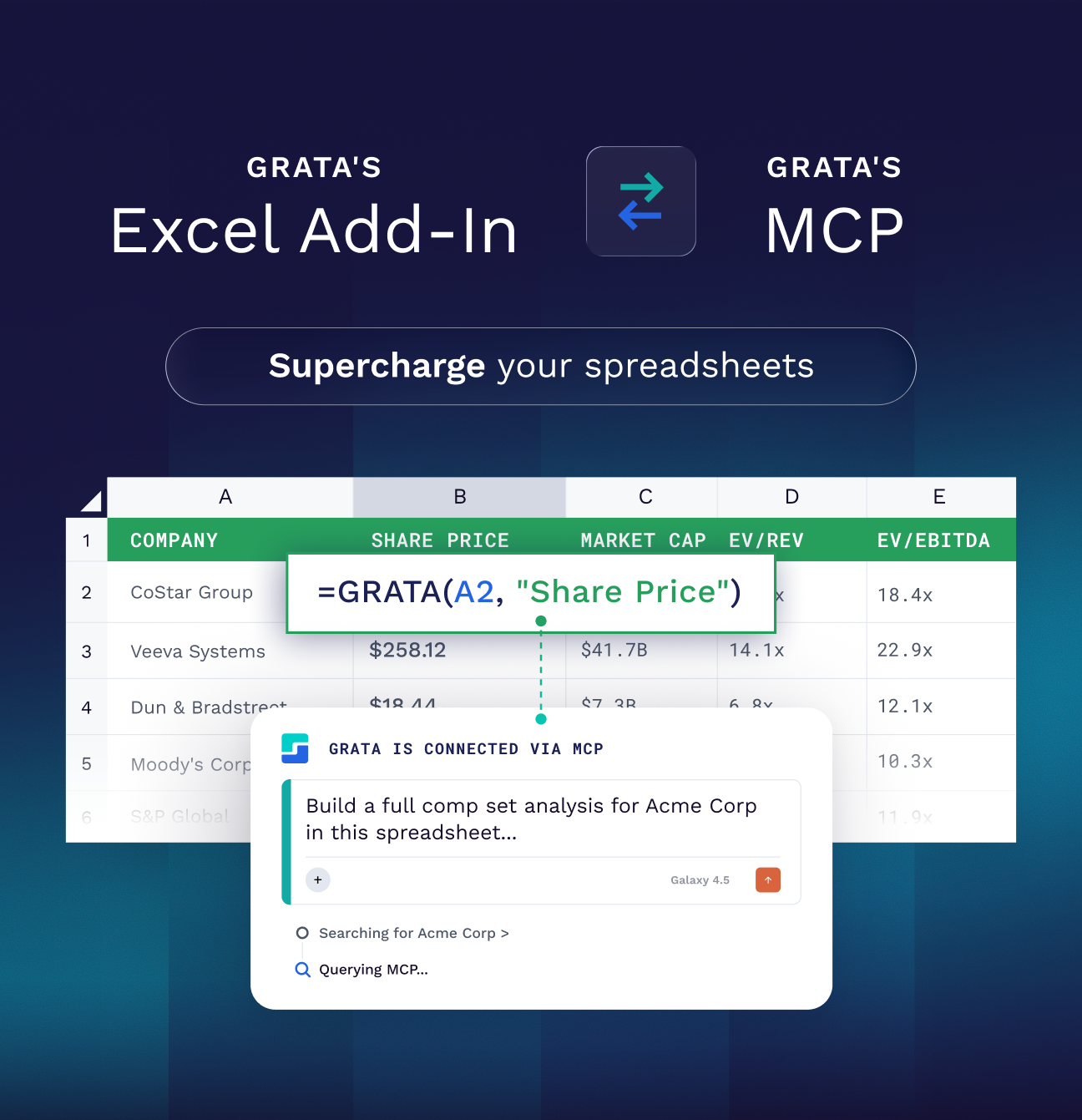
This is why a private market intelligence platform is the foundation of any AI-native sourcing workflow. For most firms, establishing this layer is straightforward: a Grata subscription gives a deal team immediate access to verified coverage of 21M+ private companies, without any custom data engineering. Some larger firms build proprietary data infrastructure on top of that, but the baseline is a subscription away.
Grata covers those 21M+ companies not by scraping the web, but by reading millions of company websites the way a trained analyst would: analyzing structure, navigation, language patterns, and commercial signals to understand what a company actually does. That data goes through a deep cleaning and reconciliation process before being audited by 600 research analysts, producing a verified private market dataset with more breadth and depth than anything an LLM can access on its own.
Grata's MCP server then makes that intelligence available natively inside the LLMs deal teams already use — Blueflame AI, Claude, ChatGPT, Copilot, and others — without requiring a separate platform.
The difference in practice:
A general AI search might surface 50 obvious vertical software providers in a given space. With Grata, a deal team might find 600 middle-market operators — founder-owned specialists, fragmented regional firms, businesses with limited web presence, and adjacent acquisition targets that wouldn't appear in any standard database.
That difference in market coverage is the difference between an adequate sourcing process and a genuinely proprietary deal sourcing operation.
Additional Reading:
With a verified market universe in place, the challenge becomes operationalizing the thesis across it. Modern sourcing is no longer keyword search plus spreadsheets. Sophisticated teams increasingly rely on semantic retrieval, structured filtering, and prioritization logic.
An AI-native sourcing workflow translates a thesis into a structured set of targeting criteria:
The shift from keyword-based search to contextual, semantic search matters here. AI-powered systems increasingly retrieve companies based on conceptual fit rather than exact match — which is why platforms like Grata's Agentic Search can surface relevant targets that a traditional keyword query would miss entirely.
When Grata's MCP is connected inside Claude, a corp dev director can type her thesis directly into Claude and have it query Grata's company universe in the same session:
"Using Grata, map the outpatient behavioral health market. Break it into segments: outpatient therapy, ABA, substance use, and eating disorders. For each segment, give me 10 example companies with ownership type, revenue range, and geography."
Claude returns a structured market map — not a list of the most-Googled names in behavioral health, but a segmented view drawn from Grata's verified private company universe. She can then follow up without leaving the conversation:
"Flag any companies in the Southeast with founder ownership and more than two locations. Those are my first calls."
The result is a repeatable sourcing process that can be applied systematically across new markets, adapted as a thesis evolves, and scaled without proportionally scaling analyst headcount.
Additional Reading:
Once a target universe exists, the challenge shifts to prioritization. A list of 600 companies is only useful if a team can quickly identify which 30 deserve outreach this quarter.
AI-native sourcing engines move from raw lists to decision-ready pipelines through layered enrichment and scoring logic.
Teams increasingly score targets based on factors like estimated seller readiness, founder age and tenure, acquisition adjacency, growth trajectory, regional density within a fragmented market, and recent executive hires that might signal a transition.
This isn't about replacing analyst judgment — it's about ensuring that judgment gets applied to the right companies, at the right time, with the right context already assembled.
One note on private company data quality: estimating scale and financial performance for businesses that don't report publicly is genuinely hard. Platforms that use conceptual inference and triangulation to generate verified estimates — rather than simply aggregating public signals — produce enrichment data that's actually reliable enough to make sourcing decisions on.
Additional Reading:
Even a perfectly built sourcing engine fails if outreach quality is poor. Founders today are inundated with generic emails that show the sender knows nothing specific about their business.
Claude can help generate personalized outreach drafts, company summaries, conversation prep, and trigger-based openers at scale. But AI-generated outreach is only as good as the intelligence behind it.
The difference between weak and strong outreach:
Weak:
"We invest in industrial services companies and think your business could be a fit for our portfolio."
Strong:
"We've been tracking the consolidation dynamics in regional wastewater compliance services, and based on your recent expansion into the Southeast, we think the market fragmentation there creates an interesting platform opportunity. We'd welcome a conversation."
The second message requires specific knowledge: what the company actually does, where it's expanding, and what the market dynamics look like. That intelligence has to come from somewhere.
With Grata's MCP connected, that workflow runs end-to-end in a single session. A BD analyst preparing outreach can prompt Claude to pull Grata's verified contact and ownership data, cross-reference the firm's CRM history, surface any prior touchpoints or warm relationship paths, and draft a personalized outreach note — all without switching between platforms. What used to require three systems and 15 minutes of manual prep takes one prompt.
For a broader look at how deal origination strategies are evolving across PE firms and investment banks, the underlying principles of relevance and timing haven't changed — only the tools available to execute on them.
Generic AI tools struggle with private market sourcing because of structural limitations that better prompting just can’t solve:
Data scarcity. Many middle-market companies have minimal public data. AI models trained on web-scraped data will underrepresent or mischaracterize companies with thin digital footprints.
Entity ambiguity. Private companies frequently have inconsistent naming across databases, filings, and directories. AI tools often fail at entity resolution — conflating different companies, missing subsidiaries, or missing the same company appearing under different names.
Ownership opacity. Determining whether a company is founder-owned, PE-backed, or in the middle of a succession transition requires data sources that go beyond public websites.
Hallucinated confidence. AI models can produce highly confident-sounding descriptions of companies based on sparse, outdated, or conflated information. In private markets, this is dangerous. A confidently summarized company that merged two years ago, changed ownership, or discontinued a product line creates real workflow problems.
Stale signals. Public web data ages unevenly. A company's website might not reflect recent executive changes, a divestiture, or current market positioning. Private market intelligence platforms with active data maintenance pipelines are materially more reliable for sourcing purposes.
Again, AI tools are only as good as the data underneath them. MCP servers can connect AI to better data, but they can't manufacture it. A connected AI workflow built on a company database that misses niche operators and lacks transaction context will still produce target lists that look complete and are not. For a detailed breakdown of where GenAI falls short in deal workflows specifically, The Shortfalls of GenAI in M&A is worth reading alongside this guide.
Additional Reading:
The future of deal sourcing is a connected set of purpose-built layers, each doing what it does best. MCP servers are what make that connection possible — giving AI assistants standardized access to the business systems and data beneath them, without custom one-off integrations for every tool.
Each layer is necessary. None is sufficient alone. The firms investing in connecting these layers — rather than treating AI as a standalone solution — are building sourcing infrastructure that compounds over time.
Additional Reading:
Until recently, connecting AI assistants to business systems required significant custom engineering for every tool and every integration. MCP — Model Context Protocol — is the open standard that changes that. It gives AI applications a standardized way to access tools, retrieve data, and coordinate multi-step workflows across systems.
Here's how it fits together in a deal workflow:
A user sends an outcome-oriented request — not a data pull, but a task. Something like: "Which acquisition targets in our CRM overlap with our new healthcare services thesis?" Answering that requires relationship context from the CRM, strategic criteria from internal notes, and company intelligence from Grata's private market database. None of that is available to Claude from a single prompt.
With MCP servers connected, Claude can discover what tools are available, query the relevant systems — Grata for company intelligence, the CRM for relationship history — and synthesize the results in a single workflow. The user gets an answer grounded in verified data from multiple sources, without switching between platforms or manually assembling context.
Additional Reading:
With the Grata MCP, deal teams can run investment-grade AI workflows that weren't possible before:
The value of Grata's MCP specifically comes from what it connects to: intelligence synthesized from foundational, private, and exclusive network data, then audited by 600 research analysts before it reaches a workflow.
Additional Reading:
Forty-seven percent of dealmakers say AI is improving visibility of risks early in the deal process, according to research by FT Longitude and the Datasite Group.
The firms that source the best deals are the ones who see the full market earlier, identify better-fit targets before processes emerge, and build relationships with founders long before anyone else is at the table.
The bottleneck in sourcing has shifted. It used to be access — getting into processes, finding the right intermediaries, building the right networks. Today, the constraint is visibility: comprehensive, verified, trustworthy coverage of a private market that remains structurally fragmented and opaque.
AI improves how deal teams reason through their market. Grata improves what deal teams can actually see. MCP is what connects the two.
The winning sourcing engine combines all three: AI-native workflows for speed and leverage, investment-grade private market intelligence for coverage and conviction, and the connectivity layer to make them work together seamlessly.
Additional Reading:
Ready to see what your market actually looks like and supercharge your M&A workflows?
Schedule a demo with Grata to explore how investment-grade private market intelligence can power your AI-native sourcing engine.
No. Claude can accelerate research, synthesis, and workflow automation, but it does not independently provide comprehensive private market visibility. Purpose-built platforms like Grata provide the intelligence layer that AI workflows depend on. When connected via MCP, Grata's data becomes accessible natively inside Claude — combining Claude's reasoning with Grata's market coverage.
AI-native deal sourcing uses AI tools across the full sourcing workflow — for thesis development, target identification, enrichment, prioritization, and outreach preparation. It's distinct from traditional sourcing in that AI is embedded in every step of the process, not bolted on as an afterthought. It still depends on high-quality underlying data infrastructure and the MCP connectivity that gives AI access to it.
MCP stands for Model Context Protocol. An MCP server is a service that exposes tools, data, and context to AI applications through that standard. For dealmakers, it's what allows an AI assistant like Claude to reach into a live company database, query CRM history, or retrieve diligence documents — rather than being limited to training data and the user's prompt. Grata's MCP server makes Grata's verified private market intelligence available natively inside the LLMs deal teams already use, enabling investment-grade sourcing workflows without a new platform or parallel process.
Private markets are fragmented, opaque, and inconsistently documented. Many companies have minimal online presence, operate primarily through industry relationships, and have limited publicly available financial data. Generic AI tools trained on public web data inherit all of these limitations. Connecting an AI to more data sources via MCP helps, but only if the underlying data is verified and comprehensive. For a detailed look at these shortfalls, see The Shortfalls of GenAI in M&A.
A modern AI-native sourcing workflow combines an AI copilot for research and synthesis, a private market intelligence platform for company discovery and market mapping, a CRM for relationship management, outreach automation tools, and diligence software for execution. MCP servers connect these layers so AI assistants can access the right data at each stage without manual switching between systems.
More likely, AI will compress the time spent on repetitive research tasks and expand analyst throughput significantly. But judgment, relationship management, thesis conviction, and diligence interpretation still require experienced humans. The analysts who thrive will be the ones who learn to direct AI tools effectively. For more on this dynamic, see How AI Analysts Are Changing the Way Deals Are Done.
The data layer. AI outputs are only as good as the visibility and intelligence underneath them. MCP servers can connect AI to many data sources, but connectivity doesn't create data quality. Investing in the underlying intelligence infrastructure — and connecting it properly — is what separates sourcing workflows that generate alpha from those that generate activity.

Monthly tactics from Grata’s team and operators.
From market trends to career advice, Grata’s content fuels smarter decisions.