.webp)
Data Analytics in M&A: Transforming Deals & Decisions
Discover how data analytics is revolutionizing M&A with data-driven decisions, big data insights, and advanced tools for deal success.

.webp)

For more insight into how to use data to build a winning M&A AI strategy, watch our webinar here.
It’s no secret that AI is changing the M&A world.
With new large language model (LLM) startups popping up all the time, it might seem like dealmakers have a plethora of tools to choose from to make their workflows more efficient.
But the vast majority of LLMs are not purpose-built for M&A. If you look behind the curtain in these new LLM platforms, you’ll find huge amounts of information scraped from public websites.
Essentially, these GenAI tools are serving up the same information you can find with a Google search — just in the form of a chat. That doesn’t do you much good if you're an investor trying to scope a market or identify acquisition targets.
So what do you need to make AI actually add value to your firm? The answer is simple — and also really complicated.
You need the right data.
Below, we break down how LLMs work and what they’re good at, why a strong data science layer is crucial for useful M&A AI tools, and why that’s so difficult to get right.
Let’s start with the basics. LLMs are AI programs that use deep learning algorithms to generate text, summarize or rewrite content, provide translation, analyze unstructured data, and more. To perform these tasks, LLMs are trained on large sets of text and data.
One of the main draws of LLMs is their ability to provide answers to unstructured questions or prompts in a logical way. In M&A, this capability is most powerful when applied through agentic search, which enables dealmakers to reason through complex market and diligence questions using proprietary data. This makes them great for customer support chatbots, as many businesses are applying on their websites and mobile apps.
Businesses can also tailor LLMs to suit specific needs and tasks. For example, companies can train their private LLMs on corporate data to help build out new products and content. Once LLMs are properly trained, they can process large amounts of data without requiring further human intervention. As a result, they offer a considerable amount of scalability.
The models can also automate data analysis, which can streamline other related tasks. Companies are putting LLMs to work in areas like:
Any AI tool is only as good as the data it’s trained on. Generic LLMs are trained to be exactly that: generic. They’re built to cover a wide range of broad topics, which means they have to ingest massive amounts of public data.
ChatGPT, and the growing crop of new LLM startups, run on data engines made up of information scraped from websites. That makes them great at tasks like summarization, text generation, writing emails, and answering questions in a chatbot.

But because they’re fueled by huge pools of public data, it’s extremely difficult for generic LLMs to get into the weeds of a given concept or process — especially when it comes to a complex industry like M&A. Additionally, the sheer amount of data that generic LLMs ingest makes them more likely to take in outdated or inaccurate information. This can lead to incorrect answers or hallucinations.

Now compare this to Grata. On the top layer, Grata’s AI is more subtle. Instead of using prompts to query the algorithm, users perform searches with keywords and specific filters. The Grata platform then returns synthesized data insights instead of long-form written responses.
With Grata, the magic takes place behind the scenes. Unlike generic LLM tools, which require a query to prompt a data pull, Grata’s AI is constantly running and conducting data analysis and quality control. This ensures that users see the most accurate data in real time.
While it might not be as noticeable on the front end, the kind of AI/data science system that Grata uses is highly complex. Data accuracy requires the ability to ingest, decipher, and reconcile multiple complex data sources — continuously. In short, it requires analytical skills, which generic tools like ChatGPT lack.

There are five key questions that Data and Product teams have to answer when conducting data analysis:
Grata’s proprietary AI models are specially trained to answer these questions. With deep in-house expertise and exclusive training data, Grata’s AI engine is equipped to recognize anomalies, reconcile conflicting data, and apply an opinionated perspective on what correctness truly means.
This approach is called "Foundational Intelligence," and it creates a digital moat that general-purpose AI simply can’t cross. Models that are trained on exclusive data will always produce better results than general LLMs.
So. What does this look like in practice? Let’s say we’re scoping out the private US HVAC market and we want to use ChatGPT to find some bootstrapped companies as a starting point.

There it is, straight from the algorithm’s mouth. HVAC is, indeed, a niche market, and there isn’t a public directory of bootstrapped companies in the space. As a result, the best ChatGPT can do is respond with what it knows: publicly available information.
The companies it listed are in the right industry, but they are all large public players or public subsidiaries — even Des Champs Technologies, which ChatGPT has described as “privately held.” These answers are too broad to be particularly helpful with our request.
So what if we feed it a specific example of the kind of company we’re looking for? Let’s try Hoffman & Hoffman Inc, a bootstrapped HVAC company based in North Carolina.


This looks like a good list of comparable companies (comps) to start with. We did a follow-up search for each company that ChatGPT provided here and found:
These might seem like small details, but inaccuracies like these cost you time. Now, instead of proceeding to the next step of your evaluation, you have to do at least one more round of searching. In the extremely competitive world of M&A, every second counts.
To that end, let’s see if we can at least get some more data points from ChatGPT to help refine our comps search.

So Hoffman & Hoffman’s revenue might be somewhere between $43M and $750M. That’s quite a range. It’s the best that ChatGPT can do given it operates with public data. Unfortunately, it isn’t very helpful for finding similar companies.
Now compare this with a platform like Grata, whose AI is trained on exclusive, proprietary data. Instead of prompting the model with a query, we can filter our search for US-based, bootstrapped HVAC companies from the beginning.

Here, instead of a handful of companies that don’t meet all of our criteria, we have over 51k companies that check every box. And if we want to narrow the pool further, we can add additional filters for employee headcount, end customers, company ratings, and more.

Grata also lets us see the full picture of the private US HVAC market by entering the same criteria into a Markets search. This shows a list of private comps, including averages for revenue estimates, employee headcounts, growth rate, and capital raised. We can also see a list of public and VC & growth comps, as well as precedent transactions, in the Market Intelligence tool.
Now, let’s take a look at Hoffman & Hoffman Inc. individually.

Grata packages all of the data we need directly on the company’s profile. We get a detailed, reliable description of its services, and we can easily navigate to see the company’s revenue, comps, executive information, and more.
If we take a look at the Financials tab, Grata estimates Hoffman & Hoffman’s revenue to be $811M. It arrives at this number based on several sources that its AI and data science technology are constantly evaluating. ChatGPT provided a wide range based on public data and still got it wrong.
Dealmakers often don’t realize that they’re sitting on a treasure trove of proprietary insights. Think about all the documents in Box, SharePoint, or OneDrive. The notes in your CRM. The detailed analyses and redlines saved in private deal rooms like Datasite. That’s not just clutter — that’s institutional memory. It reflects your firm's thinking: your strategy, risk frameworks, valuation logic, and sector views. It’s years of intelligence, captured in context.
Historically, tapping into this wealth of data has been difficult. It sat in silos, fragmented across platforms, accessible only if someone knew where to look. This is where LLMs open up a whole new frontier.
Today, with secure, private deployments of AI, firms can unlock that information and turn it into an internal knowledge base. Imagine being able to ask, “How have we evaluated supply chain risk in the past?” or “What rationale did we use to walk away from X deal?” and getting a clear, grounded answer pulled from your firm’s own deal history.
It’s like giving your entire team a shared memory that gets smarter over time. For dealmakers, that means faster decisions, better context, and more consistency across the firm. You’re capturing your firm’s IP and making it actionable.
That’s where the real edge is: not just having access to data, but being able to use it to drive better deals.
Foundational Intelligence is just the beginning. What really sets Grata apart is how we go beyond the basics to deliver Private Access and Exclusive Data insights that are hard to find anywhere else — especially for the middle market.
All of these data layers come together to help dealmakers source smarter, move faster, and make better-informed decisions in the private markets.
If you’re looking to integrate AI into your business and you’re not sure where to begin, you're not alone. The key is to start simply and intentionally.
First, identify exactly what you want AI to do for you. Think clearly about your use cases. For example, do you want AI to automate repetitive, time-consuming tasks? Pinpointing these objectives upfront gives you clarity and sets the stage for success.
Second, determine what data you’ll need to successfully execute on these use cases. We call this your Golden Corpus. It's the high-quality, trusted data that forms the backbone of your AI system. Remember, the quality of your outcomes will directly reflect the quality of your inputs.
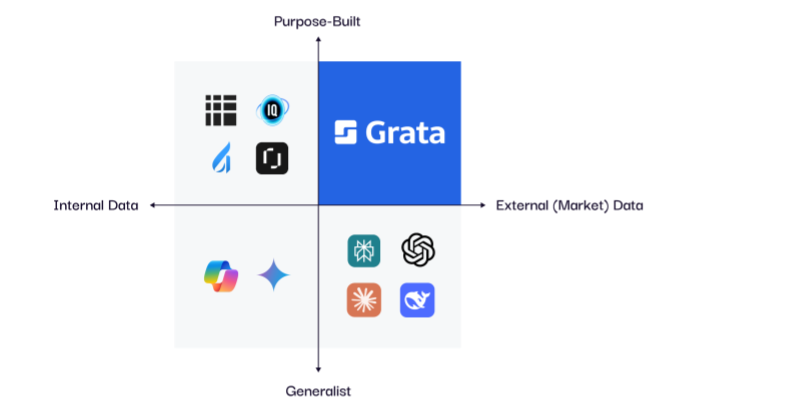
Third, choose the right AI models for your specific needs. For general purposes, leveraging commercially available AI tools like ChatGPT, or popular open-source models such as DeepSeek, is often your best bet. There's no need to reinvent the wheel here.
However, if your use case is specialized, the key is to partner with a vendor who has access to the right proprietary data. A finance AI trained specifically on robust, proprietary financial data is going to outperform one trained on the public internet every time.
Finally, perhaps the most crucial step: Establish a culture of AI enablement. Making AI a part of your day-to-day workflows represents a significant paradigm shift. Those who embrace it fully will see the greatest success. Hire and develop people who possess deep domain expertise, critical thinking skills, strong ethical judgment, and an eagerness to integrate AI tools into their daily work lives.
Ultimately, adopting AI strategically is about more than technology — it’s about empowering your team to make smarter, faster, and more confident decisions every single day. Want to learn more? Watch our webinar here.
Ready to make AI and data work for you? Grata can help. Schedule a demo today to get started.

Monthly tactics from Grata’s team and operators.
From market trends to career advice, Grata’s content fuels smarter decisions.
.webp)
